I'm somewhat surprised that this is not open source (from what I can tell). Compare to Mimo Code https://github.com/XiaomiMiMo/MiMo-Code (which is a CLI, while this is a desktop app).
Interesting to see how their harness will show up here. So far, https://cursor.com/evals this even shows still a big gap in performance, and almost no real win in terms of money vs gpt5.5 and sonnet 5.
Which make me raise a question. Why would I install a close source black box, that will send data to a country that you can't make legally liable for even most crazy miss doings.
The market of a hosted commercial version of glm is very weird. yeah you can deploy an open source version or run it locally, sure. This.... hm, i don't know why any company would take any risks to use GLM
How is this different from installing Claude Code or Codex? Maybe in the US someone has some hopes about having those makers "legally liable", but in Europe both US and China products seem equally far away and equally closed in all senses.
Z.ai documents integrations with nearly all the popular CLI-based agents: https://docs.z.ai/devpack/tool/others
If you're already used to your TUI coding agent, you don't need the desktop agent. Although it is nice that it is there for folks who prefer the Codex App/Claude App UI approach.
Yeah, I use GLM 5.2 in OpenCode, running in a Docker container with CodeNomad as the web-based GUI. It works perfectly; I can access it from anywhere, and it runs all models (except for Anthropic's subscriptions).
From your experience, is it comparable to Claude Code with Opus 4.8? How does it feel? How do the two differ?
It's comparable, but not the same.
For some tasks, it's better. Opus refuses tasks for me pretty regularly. GLM 5.2 has never refused a task. So for anything security-related or that touches on topics that trigger Opus's safety guardrails, I use GLM 5.2.
OTOH, for anything related to UI design, I use Opus 4.8. It's much better at taking relatively vague descriptions of user interfaces and a mockup of a related UI and combining them into an immaculate design.
For anything else, I tend to run tasks in Opus and then have GLM review them and write a Markdown file with anything it finds. Then I have Opus review the markdown file and fix the issues it agrees with. The reason I usually go with Opus 4.8 first is mainly that it's faster. Opus 4.8 is, on average, about twice as fast as GLM 5.2 running on z'ai's infrastructure for the same task. There's a large variance (sometimes GLM 5.2 is pretty fast and Opus 4.8 is pretty slow), but on average it's a very noticeable difference.
When I run into Anthropic's Quota, I switch to GLM 5.2 rather than Sonnet. I don't think there's much reason to ever use Sonnet for anything if you can use GLM 5.2 instead.
This is all pretty subjective, of course. On average, I think Opus 4.8 is still a better, more reliable, and faster model, but if it went away tomorrow and I only had GLM 5.2, I wouldn't be too sad about it; I'd get things done with GLM 5.2 just fine.
No. I got the yearly highest-end GLM subscription when it was available for a few hundred bucks. I haven't run into quota limits even once.
The later Opus models (4.7/4.8), Sonnet 5, and particularly Fable 5 will refuse to do tasks related to offensive security.
One example I've hit is working on a benchmark of how well LLMs handle Kubernetes security tasks, there's a section on them exploiting security misconfigurations. Opus 4.6 was fine with that section, 4.7 and 4.8 saw some refusals and Fable point blank refused to do any of it.
The only other model I've seen refuse is OpenAI GPT-5.5, all the open weight models seem fine with it.
Ofc if you need to do that kind of work a lot you might be able to get on OpenAI/Anthropics allow-list for cyber work.
One project I have deals with countries, and any time it touches code related to countries, it stops.
I've also had it refuse security-related tasks, and occasionally it stops without any discernible reason.
I’ve never had a refusal coding, and in some areas (AI red teaming specifically) I’ve found it quite good at recognizing and discussing “white hat” stuff that in the past I think would have got refusals.
But when there was the Hantavirus thing a while back, I asked it if there was a vaccine under development and got a refusal immediately. I’ve had a few like that. It seems they’ve implemented really poor guardrails on certain topics (CBRN and cyber) that have lots of false positives. But if you actually chat with the model itself it’s quite lucid about what is legitimately dangerous and what is just performative “AI Safety” style refusal.
I'm worried, but I'm worried about all of these providers. There's a good chance Anthropic and OpenAI will go bankrupt in the next five to ten years, and all of their data will go to the highest bidder.
There's no customer data sent to anyone, though. I run OpenCode and Claude Code in a Docker container that only has access to a subset of my code base. There are no secrets in there, and I'm vaguely ok with z.ai using this to train their models.
Thank you, this is the type of hands-on experience report i was looking for.
[dead]
Also, kudos to the Z.ai team for adding Linux support from day one.
I believe the incentive here is more tokens. I recall limits being more generous with their inhouse harness
[dead]
Looks quite pretty! Not sure if I want to try that instead of OpenCode, maybe. OpenCode also has a desktop app, I will admit that I like their TUI one better (and honestly more than Claude Code TUI) but whole the desktop version is kinda more basic, it's nice enough: https://opencode.ai/download
That said, it's interesting that they're releasing a bunch of stuff: ZCode, OCR.z.ai, Image.z.ai, Audio.z.ai, AutoClaw and some other stuff that https://chat.z.ai/ links to. That's a lot of stuff for one org to pull off.
Figured I'd try out their Pro coding plan, seems like it doesn't necessarily give me that much quota than Opus (at least given how many tokens are needed for accomplishing a certain task), but GLM 5.2 in of itself seems like a beefier Sonnet model, pretty good.
Their tui is quite heavy and crashing quite often as compared to claude code.
Which are you talking about? OpenCode or ZCode?
OpenCode
You can use the opencode subscription plan with other agents if you wish. They allow it
Have not used claude code but have used opencode tui a LOT and it does seem to crash quite a bit. Not like it breaks every session but enough that I have come to expect it but still not bothered enough to change. I don't like switching setups mostly
[dead]
It's impressive all these companies are getting away with "base usage allowance included" [1] or "standard limits" [2], layering the higher plans as a multiplier of that "base" but never disclosing what it is.
I guess the base is whatever the profit margin needs to be this month.
[1]: https://zcode.z.ai/en#:~:text=Base%20usage%20allowance%20inc...
[2]: https://support.google.com/gemini/answer/16275805?hl=en#:~:t...
When running the app, it actually tells you what the base usages are, but the name of the plans are different from the page. It reads:
Start plan: 5 Million tokens a day (GLM-5.2 3M, GLM-5 Turbo 2M)
For individuals: (+150% quota) $18.00USD+ For individual developers with a dedicated Coding Plan quota.
Now, if only we can figure out what all the others are providing as part of their subscriptions we can compare. (Though 3 million tokens of the top model per day seems kinda low. But, I guess that's what the 5x plan is for. I'd still like to be able to compare against all the big providers.)
Note that it says "start plan" without a price tag. The price tag for the other plan is the one on the page. I don't know what it is because I haven't set up an account to use it, I set up a custom provider in the app.
The app itself is interesting to me. I can see most of the agent trace (I can't see the tool definitions and the tool input args), I can set up skills and make the agent manage them and I can define sub-agents as well.
The UI itself is a bit weird, but I guess it's not thought to be a general purpose file editor.
You can just track the tokens used in Claude Code and codex until you hit the limit?
Can you?
Agreed this sucks. We publish ours here and try to be as transparent as possible: https://synthetic.new/rate-limits
Love both the approach and the transparency. Kudos.
Yeah, this is why I like the ACCC in Australia. They wouldn't allow this sort of thing to fly if this was an Australian company.
A strategy that can backfire. An unpredictable tool is worse than a bad tool.
no ACP support it seems :( Of all the AI buzzwords I love ACP because of the separation of concern. Let the editor be an editor, the harness be the ai code agent, and the llm be the llm
For anyone who uses GPT-5.5/Codex as their daily driver, how does GLM-5.2/ZCode compare, esp in a codebase already set up for agentic coding?
GLM 5.2 is in an uncanny valley where it's too big to run at home, too expensive and slow in comparison to similarly capable model (a good chart here - https://deepswe.datacurve.ai/), and that's just comparing API prices.
When looking at subscription offering by Anthropic and OpenAI, it's not even comparable, as a Codex $200 subscription can easily use a billion tokens per week on GPT 5.5 high/xhigh.
It's an interesting model from the perspective of being the most capable open weight model. But it doesn't have a solid place in this marketplace right now.
Thanks, that DeepSWE comparison is really useful. Yeah the Codex $100 plan with xHigh reasoning is very practical and cost efficient.
I tried it for a couple of hours this morning and yeah, it's a bit slow, and I needed it in peak hours so it also often can't reach the server so that makes it even slower. And I'm not even sure it's just the model, it could very much be the harness. Stalled for 40 minutes on trivial tool calls like `find`, two times...
It shows potential, answer/code quality was solid, but I would need more time with it.
TLDR GLM will take a lot longer to do a task, and maybe spend more tokens depending how complex it is
Its a hell of a lot cheaper though, so for me its worth it. I have more claude experience though, and I would say its almost en par with Opus 4.1
It's cheaper if you pay API prices. If you pay a gpt sub then codex is much much cheaper.
UI-wise this looks a lot closer to Codex than Claude Code. It's basically an exact copy of Codex.
I would very much agree. Even the hand icon, the usage in the text field, and the sidebar style are 1:1 identical to Codex. It's a misleading title - it's not close the Claude Code.
Which makes keeping Codex closed source look even sillier. Software is no longer anyone's moat. Just let it go.
I thought codex was open source https://github.com/openai/codex
The CLI / engine is, the desktop app and its plugins (e.g. computer use) are not.
Does anyone use an agnostic TUI or harness for development tasks that can fairly seamlessly switch between providers?
I'm wanting local context in the spirit of "here are 3 AI providers available, for coding tasks use this one... and for writing prose use this one... and for generating images use this one..." etc.
OpenCode was the first agent harness I used, and I have always like it. You can configure a wide variety of providers, but it's open source and has a number of core contributors.
The other opinionated option is Pi (the Pi agent harness). This is a great lightweight option and also supports a number of providers. You can also use local model servers.
have used both pi and opencode for the last 6 months, haven't opened a proprietary harness (cc, codex, cursor) in that same amount of time. right now i'm on pi and i can switch seamlessly between any model across any provider i want, even mid session. can even point them at locally running models.
i think people don't realize how much better life is over on this side, cc and codex rely entirely on vendor lock in imo.
Try the role-model Pi extension I built, to let Pi determine when to switch to a different model in your pool.
Does a mid-session provider switch result in loading the entire context into the new model, inflating session cost?
I don't think I understand the token/cost implications of this feature
Yes you pay a big burst right after switching. After that, everything is cached and it's smooth sailing.
Its nice if you used local, but needed å beefier modell, or more context Window. It will eat input tokens, but you do that all the time unless you have input caching.
Haha I pretty much commented the same thing one minute apart.
You can use Claude Code with a self hosted model no problem. I don't believe you can switch during a session though.
Are you using openrouter or something else?
codex is open source https://github.com/openai/codex/ it's definitely geared towards openai but it is completely open source
why did you switch from oc to pi?
i like the more minimal design of the tui, feels more integrated with my existing terminal workflows. oc always looked a little out of place. i really like pi's extension ecosystem as well.
Same here. Moving from OC to Pi also taught me one more time that less is more and I don't need most of the features I thought I needed.
[dead]
You can do this with role-model, the model router I've built. It routes based on roles and tasks among other things. It has an extension for Pi that lets your coding agent specify request metadata for roles and capabilities etc.
If you haven't yet you should give a chance to https://pi.dev
I've been using it exclusively (and extending it, see https://a.l3x.in/ai) for months with mainly GLM-4.7 then 5.1 and now 5.2 and I could hardly be any happier.
I'm still working on a "Github/Forgejo first" based workflow but also quite happy with it already, basically most of my sessions run as a ci/cd job (triggered by "/pi" comments) and generate PRs or push commits to PRs, see https://github.com/shaftoe/pi-coding-agent-action
I’ve written a skill for codex and Claude code that designates an orchestrator on the primary worktree and is agnostic about what type of AI workers are on the N supporting worktrees.
The orchestrator knows which AI client is running in any given worktree, so it would be fairly easy to designate which AI should receive what kind of tasks.
You run either Claude or Codex in tabs for each work tree. I do have some AI TUI specific instructions, for instance codex is primitive at monitoring compared to CC. So, there are additional notes for Codex workers on how to properly monitor for new "mail."
You work with the orchestrator on the primary worktree and allow it to delegates tasks to the workers and answer their smaller questions.
It surfaces results and assisting them with context clearing when needed.
The orchestrator and workers communicate using a simple shared file system under tmp/* and together they can handle a big and varied workload.
I use iterm2, so I’ve also added iterm2 specific python that allows the orchestrator to “kick” a worker or perform tasks otherwise veto'd by the TUIs (ie /clear) by modifying the input and submitting it.
Is this open source?
Circus Chief allows you to do this: https://github.com/ferrislucas/Circus-Chief
(Full disclosure: it’s my project)
I use Kilo Code for that it's based in OpenCode and it's OpenSource.
I prefer having a GUI for diffs and session history,but if you prefer TUI you can just use OoenCode
I’ve been using Crush with Openrouter and have good success lately
I stumbled upon https://omp.sh and haven't really felt the need to ever use anything different.
"omp is a fork of Pi by Mario Zechner, rewritten as a coding-first surface: sessions, subagents, slash commands, extensions — all TypeScript..."
I use the one that I've been developing since 2023. It's intended to be used in exactly this spirit! Written in Go, has image support (which has yet to be fleshed out).
It supports MCP (unlike Pi), sandboxing (with user-mode networking), and runs efficiently at huge contexts.
https://codeberg.org/mlow/lmcli
(The screenshot in the folder is a little bit out of date, but is still representative of the overall look)
Also Goose from the Agentic AI Foundation (AAIF) (subsidy of the Linux Foundation).
i like Chinese open weight model that offer cheap token but i only use it for my personal project.
China have a history of stealing IPs/trade secrets and Chinese court favored its own local companies. while US have a robust court that can enforce IPs. if you want to risk your company's IPs/trade secrets/data for some cheap token. Go ahead and use Z.ai's services.
FYI you can use Z.AI models on infra not in China...
But this harness app is chinese?
The US of A ditto
What's your top secret project?
is there cli version available for this harness?
I don't find a closed-source Chinese agent system trustworthy.
It is essentially a black box with full user permissions, meaning you are just handing over your entire system to a Chinese-owned server. With OpenCode and its GLM provider, at least I can monitor which files were read, which were edited, and what commands were executed.
Not to mention that Chinese national security laws legally obligate companies to cooperate with state intelligence and counter-espionage efforts [0]. If you have this installed on a corporate workstation, and your company is large enough, the possibility of them spying on you is not just a risk—it's almost a certainty.
[0]: https://en.wikipedia.org/wiki/National_Intelligence_Law_of_t...
I agree. I don't find the US competitors trustworthy either. I think open source is the way here.
Thank you. It doesn't make sense to me how much people trust our companies so much more than Chinese ones for no reason. This country has an abysmal track record when it comes to respecting its citizen's rights or privacy. Propaganda working as intended I suppose.
It’s not no reason. At a fundamental level I don’t trust the companies any differently. But at a professional level, nobody is going to question my using Claude or OpenAI in a professional capacity - to work on customer projects, analyze their data, etc.
I also consider Microsoft to be the biggest industrial spy in the world, them and google both are no doubt mining everything you type into office / gsuite, all your emails, etc. But nobody bats an eye when you write a word doc about some sensitive matter.
If my customers thought I was feeding their data into a Chinese owned LLM API (which to be clear I’m not), I don’t think it would go over well, and I’d be exposed legally to all sorts of things.
So the reason is risk aversion and desire to participate in US / western commerce. One can debate the actual threat, but why would you ever risk sending your data to a processor perceived as dodgy?
If you think the US has an "abysmal" track record on this, what words would you use to describe China's track record?
That's actually not beside the point as it relates to GP's comment.
This. For a typical citizen, your own government is a far bigger threat than a foreign one.
That's why, all other things equal, I try to keep my own government happy or ignorant, but don't really mind what I share with foreign governments, especially ones who won't forward the info to my own government.
Both are abysmal, but as a US citizen bad behavior from Chinese corporations and government is vastly more limited in how negatively it can impact my life in a practical way than bad behavior from US corporations and government.
Yeah, but if you reach for the top shelf every time you need a word, you can't compare things anymore.
"abysmal" probably.
depends if you look through China citizen point of view or someone in the west
China is still doing horrendous things to its population that the US stopped doing over 100 years ago. Not the same.
At least the model weights are open, I’m not American, so to me this is much more trustworthy in every possible way. You’re talking as if US intelligence are the good guys, and to me at least, they are not to any extent.
We are talking about an agent harness here, not a model.
Nevertheless, Americans thinking they are morally superior to China is always quite funny.
This administration is corrupt, cruel and doesn’t care about human rights.
And the worst is… Americans have voted for that administration…. twice!
I digress…
It didn't stop all of Facebook's behavior, far from it, but we did get to see Zuckerberg hauled in front of Senate committees multiple times (who we do vote for).
This has never happened in China, and will never happen, nor anything like it. Some open oversight is almost always better than possible secret oversight (and do you think that the Chinese government has user privacy on even its top 10 priorities?)
How is this an agent harness? It’s the harness and the model if it’s weights
foolish to blame one administration rather than all administrations since jfk was killed for trying to change things
While Trump is terrible, all the same morally questionable practices existed under Clinton, Bush, Obama, Biden. This administration just likes to brag about it. The US has been controlled by an evil technocracy/intelligence apparatus for 25+ years that gives zero f*ks about democracy or a constitution.
> all the same morally questionable practices existed under Clinton, Bush, Obama, Biden.
I’m gonna need a citation on this claim
What can you gain by looking at the weights, whether open source or not? Are they not what determines the model's output, but in an oblique way? We can't really fix the weights ourselves, weight by weight, or can we?
There's no way to safely use SOTA LLMs if privacy, and IP protection are your concern. Unless you want to spend 100k+ to host a 1T param model. Even if you use OpenCode you're sending all that information to random data centers you know nothing about.
But yes, US intelligence has killed and ruined the lives of far more people than China has. Not sure how so many people buy into the narrative that they're protecting freedom and democracy.. They're protecting their freedom to kill and crush all their enemies and control every "democracy" on earth.
You can run one on a cloud provider. You’re correct that intelligence orgs probably still can access them, but if you’re that high value of a target then you have bigger problems and / or can afford to build an air gapped system or whatever. If you’re just concerned about other companies mining your messages, self hosting in the cloud solves that.
Reminds me a bit of the old “is your adversary Mossad or not Mossad” decision matrix https://www.usenix.org/system/files/1401_08-12_mickens.pdf
"US intelligence has killed and ruined the lives of far more people than China has" - please provide a strong argument for this statement, with numbers and sources.
I'm no apologist for the US Intelligence and related organizations (not by a very long shot), but that is a very extreme statement to make.
You know what's happening in Cuba right now?
> China doesn't go around the world using it's military to force it's will upon people.
No, they use it on their own people. Come on, the USA is bad, but comparing it to China isn’t going to show the contrast you are looking for.
This is exactly the same with providers from the USA.
That's why I like to use Reasonix with Deepseek. Hitting cache makes requests basically free and that's through unsubsidized American providers like Digital Ocean or cloudflare.
You can always run it in bwrap or rootless podman.
nono, the sandboxing tool, has been working great for me
In a sense it's a clean reminder that all these, especially non-local, llm tools should NEVER run outside a container. I'm currently looking at z-jail specifically for these scenarios; VMs are too heavy & expose too many sec issues of their own for continual integrated use in my case.
Run it in a container under Opencode. It works great, and I even upgraded to their pro plan (~$60/month). If you want it in a container, there's info in my profile under my projects. That code is entirely open source, and it's there simply because I built what I needed for my own work. I'm sure there a zillion other ways to do it. However, I highly advise against running any agent on bare metal, regardless of the company's country of origin. My thesis addresses this directly and repeatedly.
By the way, some pedant recently asked why anyone would run software with only a few stars. My thoughts on that are minimal: people can practice whatever slop logic they want. I've architected and built systems that handled tens of thousands of users. I'm not fucking around. The way I build isn't typical, and I don't suggest anyone try to mimic my approach, but it works for me and the way my mind processes complex systems.
To the peanut gallery: use it or don't, but don't give me a hard time unless you're ready to get one back. I've made plenty of mistakes in my career, and accountability is a crucial part of growth. I'm more than willing to work with anyone using my code, provided they bring valid, substantial criticism to the table.
How's that different from Codex (gui app) or Claude?
Codex is open source: https://github.com/openai/codex
Well, it's different from OpenCode
The codex cli too is open source, afaik.
If you are not US based that’s not really a big concern.
I think it’s a real concern. Chinese companies are much more closely tied to the state, as in if you decide to go to China one day they might already have all the data on how you have interacted with their models.
The US is certainly inching in that direction but it’s not like someone from the US government sits at Anthropic’s HQ reading chats from state people of interest.
> all the data on how you have interacted with their models
1) there is a very non-zero chance that the US government also has that data from OpenAI and possibly Anthropic
2) unless you are asking the chinese models to draw up plans to overthrow the chinese government, it's extremely unlikely they would ever care.
while china has a track record of harassing it's own dissident citizens abroad, if you're not chinese and not trying to subvert their government (or are a high-ranking government official yourself), it's kind of silly to suppose they would ever care about you or what you do.
and if you have information they want for their own national development purposes, like EUV engineers, they are much more likely to offer you fabulous amounts of money instead of try to intimidate or threaten it out of you.
I agree, but considering the age of AI was ushered in with the largest and most complete theft of IP in human history, from inside the good 'ol USA, we shouldn't trust any LLM provider with critical information of any kind, and instead push even harder for better local models.
even companies that proclaim zero data retention have yet to produce a mechanism that makes me trust that claim
> if you decide to go to China one day they might already have all the data
PRISM ... XKeyscore ...
> The US is certainly inching in that direction
Itching to go in a direction that (publicly known) they have been in for decades now.
At this point i think the china mass surveillance was propaganda while the USA one is for real.
It's interesting how you would say this about China but not about the US, especially given what's happened recently with Anthropic and the US govt.
Do you really think the US government doesn't get access or couldn't get access to any of your chats with Claude?
Hmm yeah I really think that the US government doesn’t have access to my Claude chats and wouldn’t be able to without jumping through actual legal hoops like a subpoena or other legal order. More than happy to be wrong if you have a source that points in that direction.
yes but the americans are also doing it, and i don’t really work on anything worth spying on
NSA can also legally force companies to spy. Secret spy courts and gag orders are a thing.
Actually there are more such cases against the USA than China in public.
I'm in the US. The benefit of the Chinese spying on me vs a US company is the Chinese can't come to my door and take me to jail.
As someone who loves using OpenCode w/ local Chinese open source models, this is basically my take on this as well. There's no way I would ever put a piece of proprietary Chinese software that gets full system control on anything important. This is definitely something I would only ever run sandboxed in a lab environment for toy projects, not for serious work. I feel only marginally better about Codex/Claude Code, hence my strong preference for local LLMs w/ OpenCode, but a proprietary approach to Chinese models is a hard no from me dawg.
so basically no worse than europe or usa, but they are just more open about it
> It is essentially a black box with full user permissions,
You mean, like Windows and Android?
For GLM Coding Plan subscribers, quota consumed via Coding Plan for GLM-5.2 in ZCode is discounted by the coefficients below — the same usage draws down less quota, roughly 1.5x the effective allowance.
Peak hours (14:00–18:00 daily) 3x -> 2x
Off-peak (remaining 20 hours) 1x -> 0.67x
From https://z.ai/subscribe#code-plans-container:
> Explanation and Recommendations Regarding Usage for Plan-Supported Models
> Note: Peak hours are from 14:00 to 18:00 daily (UTC+8).
Peak hours are 14:00–18:00 (UTC+8)
Thanks. Those are some odd hours though, why would evening time be peak hours? Usually (in the western world anyway), 9AM - 12PM would be peak hours. Things normally slow down post-lunch, and be its slowest at close-of-business.
I run a corporate AI server and coding peak hours here are 1PM-5PM judging by AI usage stats. My guess is that people spend 9AM-12PM in meetings and at lunch, and the actual coding starts around 1 PM.
Because westerners are using it is my guess and for them that's right in your window
They're peak hours in Beijing
if you're going to try this one out, don't be surprised to get this message repeatedly, like 4 out of 5 prompts you're trying to send, 24/7, this is gonna be your new friend, then you'll learn to write the only prompt that matters: "retry", "retry", "retry"
Here's the message: "Cannot connect to API: write EPIPE"
When the harnesses commoditize, it will be the dynamic things like skills that will be the most valuable, useful thing you can bring to a harness. That seems like a long ways away though. There are still meaningful performance differences between agent harnesses.
Can anyone tell me if Z.AI's cheapest plan is more or less generous than Claude's cheapest plan? If it is more or less generous, could you describe the extent of the difference?
(If this comment is too formal, I'm sorry. I used Google Translate to it [this line was NOT translated])
I got around 17m tokens on glm 5.2 then blocked for 4 days on the weekly limit on that plan.
17M tokens... I think it is a lot. What were you working on?
Is that 17M output tokens?
At 200k context that is only 85 requests for a whole week.
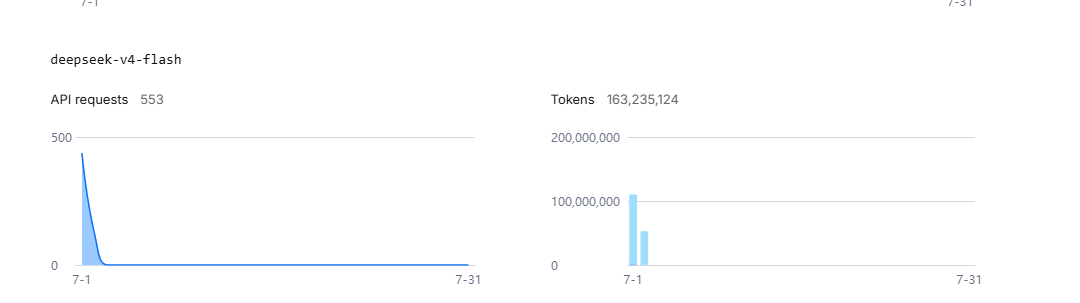
Not really. I have spent 163M deepseek v4 flash tokens in July and it literally just started.
I definetily cannot spent too much token in a single month
That's like 30 minutes of MCP usage.
Closed source? No Thanks
This isn't a CLI, so not really like Claude Code. Looks more like Cursor or Conductor.
The plans on first glance is the same as Anthropic’s. I thought GLM was supposed to be cheaper. Am I missing something?
I haven't tried Z.ai, but both Ollama ($20) and OpencodeGo ($10) seem to give me more generous limits than the Claude $20
They give you much better quotas, on the 20USD plan using opus you will quickly run into limits.
The plans may have comparable prices, but the API rates are much cheaper. Especially because it is open weights, so there is competition on places like OpenRouter.
separation of model and tooling is as important as legislative and judicative, and just ignore any tooling or harness not true open source. they will all slowly creep into your life and choke you trying to lock you in.
Is this GUI only?
Yes.
As someone who doesnt use these tools, why does every AI company need their own version of Claude Code? Is there more to it than vendor lock-in?
"Quality" of the harness matters a lot to the user experience, and the construction of the harness will depend on the behavior/quirks of the underlying model. So, if you're using Claude Code, you can expect it to work best with Anthropic models, and expect other model-makers to want you to use the harness they've developed.
But mostly vendor lock-in, I imagine.
There are different grades of vendor lock-in. There's mechanical lock-in (which is a thing, like .claude folders) and economic lock-in but then we don't pay enough attention to behavioral lock-in. Habit is powerful, and if you can habituate users into a certain flow, change feels bad and they are more likely to stay.
Why not? They are relatively easy to make so why not. Even I made one: https://github.com/computerex/z
implementing their own version of steganographic monitoring lol
A joke but also not a joke.
sweet! i'm heaviliy using glm 5.2 in mouse.dev which is great for mobile. the ui looks really good, similar to cursor agents window ect.
What’s with the 3 subscription plans that are suggestive of being mapped to plans from Anthropic and Open AI?
Do they really correspond roughly? Seems like they’re trying to suggest a discount while still being worth a significant amount of monthly spend.
It's sad to see that the teams that have the most resources that can contribute to development of next-gen harnesses are essentially copying the same exact thing from each other, with no meaningful changes.
And most of the advancement and experimentation happens in some random 0-star github repos.
Could you share some of these 0-star github repos?
I've been working on my own private harness for the past 8 months, and I've been collecting ideas from such repos I've stumbled upon.
pi-tmux is one such example (seems to be archived now) which inspired me to use tmux as communication layer and provide visibility of subagents of multiple models in their native harnesses [1].
There's also herdr, which is not 0-stars, but is super interesting but lesser known project [2]. This also has interesting substrates to allow agent coordination.
None of these are harnesses per se, but they're pointing towards clear gaps in existing harnesses. For example, we've known for a while now that compounding knowledge of different class of models achieves better performance. Why is there no harness where this is a native functionality? And there's no harness where subagents are first class citizens both in terms of capabilities and UX.
There the ones with most to prove
First-party harnesses are great, but i'd really wish this was a CLI and not a GUI
I could use them as a provider if they shown concrete price per token. Or concrete number of tokens in each plan. Now I don't know what I would rent from them. If I were to buy hell knows what, I would go to Anthropic.
I don't get why not open source it? You are already open-sourcing your weights!
Because a harness can more easily stop backdoors of a model. A packaged app on the other hand ... let's say I'll skip this until I can compile and package it.
One of these is not like the other.
I've been using this for a few weeks and it's a real workhorse.
Has anyone come up with a decent harness for small local models, say, gemma4 e4b? I'm trying to roll my own but man, the capability gap is real.
This is precisely what I've been working on targeting with https://dirge-code.github.io/
I've written up an explanation of what trips small models ups and how the harness can address that here https://yogthos.net/posts/2026-06-08-dirge-code.html
Very interesting work! I put some effort into getting it to work with models my hardware can actually run well and they just fall over immediately. gemma4 12b runs like molasses on my 2080 super but it was the only model able to, with your harness, actually do anything useful. It was the only useful thing I've gotten any model runnable with my hardware with any harness I've tried, very impressive!
I suspect smaller models need more work than is practical to fit harnesses around. The smaller the model, the more work, and it doesn't carry over to other small models.
Deepseek r1 7b could not emit tool calls to save its life, gemma4 e4b couldn't get the names of files right, qwen3.5 4b gets stuck in dumb rabbit holes, I pointed it at a ruby script and asked it to run it, it tried running it with bash then got caught in a loop investigating.
Noble effort though! I guess I'll keep working on my barebones ruby_llm harness, with very tempered expectations. Each of these failure modes can be worked around, but there's too many of them to work around in the general sense.
Thanks, glad to hear the harness is actually doing its job with smaller models on your end. There definitely seems to be a limit of how small a model can get before it can't do any practical work.
I find I tend to view agentic coding similarly to a genetic algorithm. The model is the mutator function, and the harness along with the tests acts as the selection function. Each round the model generates some plausible code, it gets tested against the constraints, the model gets feedback and iterates on it until it converges on something that's workable. So, the real trick is to make sure the environment is producing correct pressures to guide the model in the needed direction.
Another interesting project in this space I can recommend checking out is ATLAS https://github.com/itigges22/ATLAS
Do you have benchmarks comparing against Pi? The blog post doesn't include any hard numbers.
For example, so far I haven't seen any evidence that LSP integration improves performance for small models vs using grep via a bash tool.
I haven't really seen anybody come up with a good test to show hard numbers on comparing agentic harnesses. It's a bit tricky to set up a definitive test given the whole non deterministic nature of LLMs. What I've been focusing on is watching the loop and seeing where model does things that it shouldn't have to. For example, I notice models doing stuff like writing python scripts to match parens for Clojure all the time using editors like Pi. So, having a mechanical way to repair parens, and when that fails, to give the model clear error regarding where syntax is broken removes that whole cycle.
As it stands, it's kind of subjective, you just have to try the harness and see if the model seems to be have better than with the other ones you've been using.
How are you iterating on a system prompt and tool descriptions without an eval that gives you hard numbers for improvement or regression?
This really resonates. Thanks for mentioning.
This is very impressive!
Thanks, it's been a fun and educational experience working on the project.
literally I paid in the morning for the pro plan and then they launched this. currently are my fav lab after Anthropic.
Lucky you! I'm considering switching from Kimi 2.7. What's your experience so far?
Try to understand the token usage/cost with subscription plan comparing with Claude Pro. Is there benchmark somewhere for such info?
I think they market is as 3x the usage for the same price. Although, the prices are not the same, and Anthropic's usage constantly changes, so...
it's an electron app, it highlights wrong spelling but doesn't suggest corrections. how does someone exhibit so much incompetence?
Welcome to using v1.0.0 of any product
v3.2.2 as of today
Does it support Azure openai and aws bedrock models as well?
Coding plans are often out of stock, it's miraculous
how is this cheaper?
Is there any desktop coding app that can be used with local LLM?
OpenCode (TUI and desktop app) can use Qwen local
I built vibn.dev for this purpose, it’s very rough around the edges tho
Yea not touching this with an any-foot pole. They are just keeping up with the Joneses now. There is no reason for this to exist but there IS a reason it is not open source. ;)
Isn't competition and open markets a reason for this to exist?
Funny, I think the same about Claude.
Didn't Claude Code pioneer this style of agent?
They said Claude, not Claude Code.
Is it possible to use their subscription pricing with Opencode?
I use the coding subscription in both Pi and OpenCode without issue.
This comes with a little bit of free credits. (after login)
It did last week. Wow. That didn't last long.
I couldn’t find if it is soc 2 etc
Those are some odd hours though, why would evening time be peak hours? Usually (in the western world anyway), 9AM - 12PM would be peak hours.
Z.ai is based in China and serves out of Singapore, that's surely why.
cool to see how fast they are catching up
eager for zcode-cli. and their coding plan is always selled out.
Is there a CLI version of it?
OpenRouter + Current IDE for me. Cant be buying a new plan and change IDE every time a new model drops beyond testing for curiosity.
I tried it but went back to OC, which feels smarter.
It does have a 1.5x usage promotion for GLM 5.2 on the coding plan so now is a good time to test it...
GLM-5.2 seems capable. It’s just much slower than Opus.
There are now more and more Harness clients. I hope we can have the best open-source client and the best open-source models, as this would greatly facilitate our work and operations. However, this seems unlikely in the short term.
With Musk buying Cursor, it is good to have more alternatives on the market.
what is then VS code with GitHub Copilot ? It primarily does the similar things.
For those that want something based on Pi Mono:
- https://igorwarzocha.github.io/howcode/
- https://github.com/ruuxi/stella
Not using Pi, but based on PI (no extensions possible)
GLM-5.2 is a great model!
But it already works really well with existing harnesses, I'm not sure why a dedicated one is needed?
I use it with https://swival.dev and everything works perfectly, no tool calling issues and it works fine with long sessions.
Telemetry enabled?
How about no? I'd rather use something open source and local. We have enough of 3rd party controlled AI tools.
[flagged]
[flagged]
[flagged]
[dead]
[flagged]
[dead]
The original submission was to [0] which I feel must be mentioned.
You're referring to https://news.ycombinator.com/item?id=48751752, which was the third submission of this. The original submission was in fact to https://zcode.z.ai/en, so I took that one and re-upped it in order to have a place to merge the thread. Seemed fairest!
{kind=link}
I don't even know what I would do with a desktop app. I'm running these things in headless VMs, so I can run them with `--dangerously-skip-permissions` or whatever. I don't trust them, even without that flag, on my desktop/laptop.
Good desktop apps in this category can manage agents across any number of remote SSH hosts.
But, it's still running on my desktop/laptop. I don't trust them to run on my machine. But, I guess I could run one VM with a desktop to contain the desktop app. Or, just keep using CLI agents.
For local tasks you can only give agents delegated that execute your deterministic read or write on an allowed set of files(e.g pi does this) and execute rights only on containers with no network access. That should get you 95% unblocked for most tasks you want to do with an LLM pretty safely.
You can do a brainstorming with web on a remote container prototyping based on that brainstorm on another container with no network access.
The one thing that is less trustworthy is using local agents for service management, you definitely want to have them scoped to dev/testing. I would never trust an agent to execute any command in production or sensitive data at all
I don't run agents directly on my desktop/laptop machine. I run them in VMs or containers (sometimes in containers on VMs). There have been too many credentials stealing exploits via prompt injection and the like for me to be willing to let an agent roam around on my personal system.
I've also started creating new github deploy keys for each repo in use on a VM, so the blast area for any given agent disaster is "a couple/few github repos and whatever credentials were needed for the agent/model".
I wouldn't let a coworker, even one I know pretty well, log into my personal account on my machines...why would I let an agent that can be tricked into uploading all my credentials to an attackers web server?
The agents have sandboxes, but those are loose. Not enforced by anything outside of the agent harness itself.
I don't run anything but the agent and the project it's working on and the tools it needs to work on the project in the VM.
You can't see how the agent having no access to anything other than what it's working on is safer than the agent having access to my home directory with all of my credentials?
Look, you do whatever you want to do with your agents and your computer. I'm going to...contain them.
https://venturebeat.com/security/six-exploits-broke-ai-codin...
Seriously, you dont see any difference? A agent is non deterministic and may delete or change you data as a normal matter of operations. A browser, barring bugs or security issues, would not delete or modify the data you have outside the browser.
Slop is less of a problem than the incentive such companies have to “accidentally” hoover up whatever data is accessible.
But then I close my laptop and it’s not running on the headless host anymore right
That's also true if you're running the agent directly on your laptop OS.
In that case, maybe you want VMs at hosting providers. There are companies building ephemeral VM and container orchestration layers for this kind of thing, I haven't played with them, though. It seems like a reasonable idea, though. One isolated environment per project or repo. Only the secrets needed for that one project and an agent that can't reach outside of it.
I've considered building something along those lines, and actually do run my security auditing benchmarks in containers automatically (that was originally to prevent the models from cheating, because you can disable network, but it has other pleasant side effects).
It's actually not that big of a lift these days to spin up containers on-demand and put just what's needed inside it (including the authentication info for the agent). I probably should automate it..right now I just have four permanent VMs setup for my various types of work: My day job, my open source projects, my benchmark and security work, and some side projects. Plus some temporary ones for experiments.
No, it actually continues running headless on the host, and you can reconnect from another laptop or mobile phone, or even ssh to the host and attach to the session. At least Codex desktop app works this way.
Codex, Claude Code, ZAI — they continue work in headless mode, when you close your laptop, if you have connected to remote machine
Examples here?
[dead]
What's stopping a CLI from doing the same?
I've never used IDEs and never will, why are these things being constantly shoved down our throats?
I've contributed to https://github.com/0xferrous/agent-box which allows you to bind-mount git repositories into containers that agents operate in, preventing the agents from accessing files that aren't bind-mounted. Your usual .gitignore can then be used to also ignore files within the repo to be bind-mounted, which prevents agents from accessing them at all, essentially working as a sandbox.
I also maintain https://github.com/nothingnesses/agent-images which allows you to use Nix to reproducibly spin up OCI container images containing agents and any other tools you need for development and use these with agent-box.
I use both at the moment to work on some personal projects with agents, where I set up multiple separate git worktrees for the agents to work in, preventing them from accessing anything outside of the worktrees and from trampling over each other's work.
In case anyone is interested, I'm also using bash scripts to run my agents in containers. It's simple, but has only bash and docker as dependency: https://github.com/asfaload/agents_container
a well-design IDE should abstract that away, i.e. run the agent in the headless VMs while give you an abstraction that you would feel like you are running the agent locally with all the benefits (editor, browser, diffs, debugger, etc)
I shared your fear some weeks/months ago so I was always using my harness in the cloud. However, latency started to become an issue when I traveled to other countries where I needed a VPN... so I ended up cooking skynot to be able to trust running my harness in my own computer: https://github.com/tarsgate/skynot (PRs welcome if you want to add support for another harness different than Pi)
> I'm running these things in headless VMs
What's your setup like and what do you use it for?
I have a M2 Max MBP with plenty of ram and I use VSCode + Zoo Code plugin with Qwen3-Coder-Next-GGUF:UD-Q4_K_XL to run local agentic coding sessions, but I'm intrigued by being able to run headless as I could probably run multiple instances in parallel to do stuff?
Like are you using UTM with some pre-built VM and a local LLM?
Curious.
Might wanna check out https://github.com/LuD1161/agentjail - policy guardrails for coding agents.
shameless self-plug. I've been dogfooding it for the last 3 weeks now.
Looks similar to https://github.com/nolabs-ai/nono. Maybe one day you can fill out https://github.com/LuD1161/agentjail/issues/10 with a comparison to that project too.
Zcode allows you to connect to a Docker container, or to a VM using ssh.
I finally repurposed an old server just for that and for anyone reading who has not had a chance to use --dangerously-etc. it's awesome, do it :)
I just back up my entire home folder to another device, then let it rip
It's only a cli because they yanked out the opencode desktop code. (As well as the opencode go/zen model provider)
Edit: my theory is they wanted to mimic being the primary provider in a quick way with a lot of string replace. Though they could have added opencode back as a regular provider.
MiMo Code adds a lot of cool orchestration features to OpenCode! It definitely is NOT a quick find-replace job, it's genuinely someone's research project to create a better agent harness building on top of free software, and that's awesome. See https://mimo.xiaomi.com/blog/mimo-code-long-horizon
They did remove the opencode provider though and the desktop and web interfaces. I was trying to be charitable.
By the way, their repo was a bit weird with no changelogs at all. It seems to be picking up speed now with their communication. I actually read in the changelog just now that their Compose (plan/executre/review etc. something like that) flow is now deterministic with software instead of just prompts. That could be really good.
You're surprised? I think harnesses are almost as important as the underlying model. Folks have been able to improve benchmark results by nearly 2x based on harness alone.
Harnesses are quickly becoming critical components of the "model" itself imo. Not shocking to me at all that a company that spots a revenue opportunity is keeping its harness closed source.
I'm a neophyte. What makes a harness special or all that unique from another? I've had a reasonable experience with Zed and local models, but could be persuaded to put something else in the mix if there is a measurable benefit to be had.
Simple example: a while back LLMs would trip over questions like "how many Rs are in strawberry". Now, the system prompts have a line like "when a user asks for a count, actually count the value by calling a tool if needed". The LLMs cannot get smarter in this regard, next token predictors will hallucinate here.
A harness is that covering every blind spot or sub-optimal but probable output people have hit in the wild, and a lot of problems just have better solutions if you say "break problem A into subproblem B and subproblem C, then solve".
Source? The most trusted benchmark right now (deepSWE) scores better or just as well on their minimal harness than when using CC or codex
They might be sending some user requests to Anthropic to gather trading data for their own models. If they do so, perhaps they need to add some tracer to request that they prefer to hide.
I wonder if you're as cynical and untrustworthy of American companies as well or is it more of a racism kinda thing
Everyone should distrust them equally. Only local agents in a detached network namespace are safe from data leaks. It is perfectly reasonable to assume they are using our sessions to train on, since everything else short of nuclear launch codes is already there, and they need to keep feeding it.
This is an extremely weird comment that doesn't add anything to the conversation.
Here on HN we discuss facts, jumping straight into racism has no place here.
Wireshark would catch that easy-peasy.
The request would need to be done from their service, so as not to expose the API key, and because it just makes sense. They could probably directly proxy it and Wireshark couldn't catch it, due to everything being HTTPS. But people could probably catch it by decompiling, so it would make more sense to have the server make the request as part of a GLM request. Not that I think this is plausible - I'm not sure.
Source? Or is it "trust me bro"?
"might" means pure speculation
Literally just FUD unless someone has code to point at.
Those nefarious distillers, only we are allowed to freely distill the world’s knowledge into our paid products
or more likely, sending it to the CCP
Californian Communist Party?
California has had a ban on the Communist Party since the fifties.
Given that there's such severe concern being expressed by Anthropic about Claude being distilled, and the idea that the harness is part of the the moat, it doesn't seem super surprising that the other side of that would try to also make it harder for them to tell how well they're doing and what their approach is.
Unlikely considering they’re publishing the Crown Jewels (GLM 5.2) as open weights.
> and the idea that the harness is part of the the moat,
That idea is wrong, though. These same people thinking harnesses are part of a moat are also boasting that s/ware is easily writable now.
There's no secret sauce in a harness that you can't vibe-code into your own harness.
Why don't the major players open source their harnesses then? As far as I'm aware, the only time the source code for the Claude harness became available, it was due to a mistake (which is it's own whole thing).
I'm not saying you're wrong necessarily, but I do think that when the actions and words of a company conflict, it's a pretty safe bet that the words are just posturing and the actions better reflect their actual belief. In this case, regardless of what they're saying about software being easily writable now, they clearly seem to at least think there's something valuable in the harness if they're not open sourcing it.
> vibe-code into your own
Except you'd need the knowledge of what to vibe-code, no?
> Except you'd need the knowledge of what to vibe-code, no?
What knowledge? If you've used a harness, you know what it is supposed to do for you!
What further knowledge do you need that can't be extracted from an existing harness?
I don't find a closed-source Chinese agent system trustworthy.
It is essentially a black box with full user permissions, meaning you are just handing over your entire system to a Chinese-owned server. With OpenCode and its GLM provider, at least I can monitor which files were read, which were edited, and what commands were executed.
Not to mention that Chinese national security laws legally obligate companies to cooperate with state intelligence and counter-espionage efforts [0]. If you have this installed on a corporate workstation, and your company is large enough, the possibility of them spying on you is not just a risk—it's almost a certainty.
[0]: https://en.wikipedia.org/wiki/National_Intelligence_Law_of_t...
You shouldn’t find American ones trustworthy either.
I am not surprised it is not open source. These harnesses are hard to build - they are not just wrappers - and often they contain business logic that is not suitable for public distribution for all kinds of reasons.
hard? wut lol....
no. they. are. not.
Some people are just terrible at it.
I was thinking the same and I changed my mind.
Also you don't need to believe me. There is enough evidence in the open source space.
I'd prefer a CLI over a desktop. But then why don't I just use OpenCode?
That looks to be a copy of OpenCode
A fork, yes.